Современные большие языковые модели, такие как Claude, коренным образом изменили взаимодействие человека с технологиями. Они лежат в основе чат-ботов, помогают в написании текстов и даже способны создавать поэзию. Однако, несмотря на их впечатляющие возможности, принципы работы этих моделей во многом остаются загадкой. Часто их называют «черным ящиком», поскольку мы видим результат их работы, но не понимаем сам процесс принятия решений. Такое отсутствие прозрачности создает серьезные проблемы, особенно в критически важных областях, таких как медицина или юриспруденция, где ошибки или скрытые предубеждения могут привести к реальному ущербу.
Понимание механизмов работы больших языковых моделей является ключевым фактором для построения доверия. Если невозможно объяснить, почему модель выдала конкретный ответ, трудно полагаться на ее результаты, особенно в чувствительных сферах. Интерпретируемость также помогает выявлять и устранять предвзятость или ошибки, обеспечивая безопасность и этичность моделей. Например, если модель систематически отдает предпочтение определенным точкам зрения, понимание причин этого позволяет разработчикам внести необходимые исправления. Именно эта потребность в ясности стимулирует исследования, направленные на повышение прозрачности работы ИИ.
Компания Anthropic, разработчик модели Claude, активно работает над тем, чтобы «открыть» этот «черный ящик». Недавно исследователи добились значительного прогресса в понимании процессов мышления больших языковых моделей, и их достижения проливают свет на внутренние механизмы Claude.
В середине 2024 года команда Anthropic совершила прорыв, создав своего рода базовую «карту» того, как Claude обрабатывает информацию. Используя метод, известный как обучение словарю (dictionary learning), они выявили миллионы паттернов, или «признаков», в нейронной сети модели. Каждый такой признак связан с определенной концепцией или идеей. Например, некоторые признаки помогают Claude распознавать города, известных личностей или ошибки в коде. Другие связаны с более сложными темами, такими как гендерная предвзятость или конфиденциальность.
Исследователи обнаружили, что эти концепции не локализованы в отдельных нейронах. Напротив, они распределены по множеству нейронов сети Claude, причем каждый нейрон вносит свой вклад в формирование различных идей. Именно это пересечение затрудняло выявление конкретных концепций. Однако, идентифицировав повторяющиеся паттерны, исследователи Anthropic смогли начать расшифровку того, как Claude организует свои «мысли».
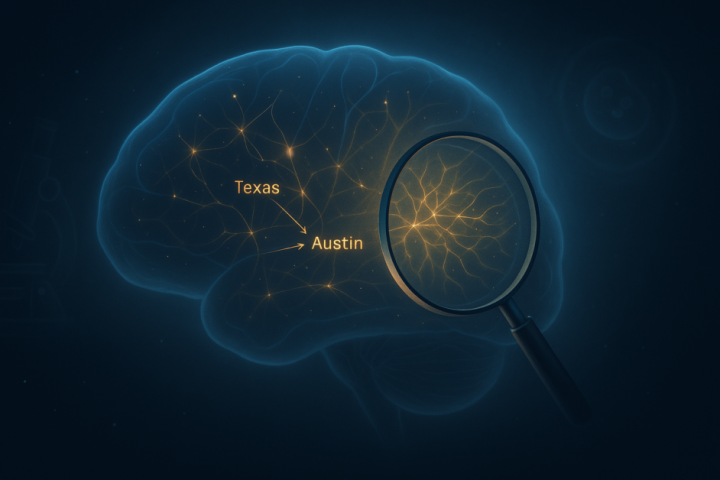
Следующим шагом для Anthropic стало изучение того, как Claude использует эти выявленные концепции для принятия решений. Недавно был разработан инструмент под названием графы атрибуции (attribution graphs), который функционирует как пошаговое руководство по процессу мышления Claude. Каждая точка на графе представляет собой идею, активирующуюся в «сознании» модели, а стрелки показывают, как одна идея перетекает в другую. Этот граф позволяет исследователям отслеживать путь от вопроса к ответу.
Для иллюстрации работы графов атрибуции приводится пример: на вопрос «Какая столица штата, где находится Даллас?» Claude должен сначала определить, что Даллас находится в Техасе, а затем вспомнить, что столицей Техаса является Остин. Граф атрибуции точно отображает этот процесс: одна часть модели идентифицирует «Техас», что в свою очередь активирует другую часть, ответственную за выбор «Остина». Команда даже провела эксперимент, искусственно изменив активацию части, связанной с «Техасом», и, как и ожидалось, ответ модели изменился. Это демонстрирует, что Claude не просто угадывает, а последовательно решает задачу, и теперь этот процесс можно наблюдать.
Значение этих разработок можно лучше понять по аналогии с прорывами в биологических науках. Подобно тому, как изобретение микроскопа позволило ученым открыть клетки – скрытые строительные блоки жизни, – инструменты интерпретируемости позволяют исследователям ИИ обнаруживать строительные блоки мысли внутри моделей. И так же, как картирование нейронных цепей в мозге или секвенирование генома проложили путь к достижениям в медицине, картирование внутренних механизмов Claude может открыть дорогу к созданию более надежного и управляемого машинного интеллекта. Эти инструменты интерпретируемости играют жизненно важную роль, позволяя заглянуть в процесс мышления ИИ.
Несмотря на достигнутый прогресс, полное понимание больших языковых моделей, таких как Claude, все еще далеко. В настоящее время графы атрибуции могут объяснить лишь около четверти решений Claude. Хотя карта признаков впечатляет, она охватывает только часть того, что происходит внутри «мозга» модели. Claude и другие LLM с миллиардами параметров выполняют бесчисленное количество вычислений для каждой задачи. Отследить каждое из них, чтобы понять, как формируется ответ, сродни попытке проследить за каждым нейроном, срабатывающим в человеческом мозге во время одной мысли.
Еще одной серьезной проблемой являются «галлюцинации» ИИ. Иногда модели генерируют ответы, которые звучат правдоподобно, но на самом деле являются ложными, например, уверенно заявляя неверный факт. Это происходит потому, что модели полагаются на паттерны из обучающих данных, а не на истинное понимание мира. Понимание причин таких отклонений остается сложной задачей, подчеркивающей пробелы в нашем знании их внутренних механизмов.
Предвзятость представляет собой еще одно значительное препятствие. Модели ИИ обучаются на огромных наборах данных, собранных из интернета, которые неизбежно содержат человеческие предубеждения – стереотипы, предрассудки и другие социальные недостатки. Если Claude усваивает эти предубеждения во время обучения, он может воспроизводить их в своих ответах. Выяснение источников этих предубеждений и их влияния на рассуждения модели – сложная задача, требующая как технических решений, так и тщательного анализа данных и этических соображений.
Работа Anthropic по повышению понятности больших языковых моделей, таких как Claude, является важным шагом на пути к прозрачности искусственного интеллекта. Раскрывая, как Claude обрабатывает информацию и принимает решения, компания способствует решению ключевых проблем, связанных с подотчетностью ИИ. Этот прогресс открывает возможности для безопасной интеграции LLM в критически важные секторы, такие как здравоохранение и право, где доверие и этика имеют первостепенное значение.
По мере развития методов повышения интерпретируемости отрасли, которые с осторожностью относились к внедрению ИИ, могут пересмотреть свои позиции. Прозрачные модели, подобные Claude, указывают путь к будущему ИИ – машинам, которые не только имитируют человеческий интеллект, но и могут объяснить свои рассуждения.