
Глубокие нейронные сети (DNN) произвели революцию в машинном обучении, но их успех не соответствует классическим ожиданиям. Они работают исключительно хорошо даже в сценариях с завышенными параметрами, где модели содержат гораздо больше параметров, чем точных данных. Эта, казалось бы, парадоксальная способность к эффективному обобщению озадачивала исследователей на протяжении десятилетий.
Новое исследование Оксфордского университета, опубликованное в журнале Nature Communications, проливает свет на это явление, выявляя замечательную особенность глубоких нейронных сетей: встроенную форму бритвы Оккама, которая способствует простоте.
Глубокие нейронные сети преуспевают в контролируемом обучении, когда они предсказывают метки для невидимых данных после обучения на примерах с метками. Обучение предполагает минимизацию функции потерь, которая измеряет разницу между предсказаниями сети и истинными метками.
Несмотря на свою способность адаптироваться практически к любому шаблону данных, глубокие нейронные сети, как правило, находят решения, которые хорошо обобщают, — решения, которые работают не только с обучающими данными, но и с новыми, невидимыми входными данными. Эта замечательная способность, как утверждается в исследовании, обусловлена их врожденным предпочтением более простых функций.
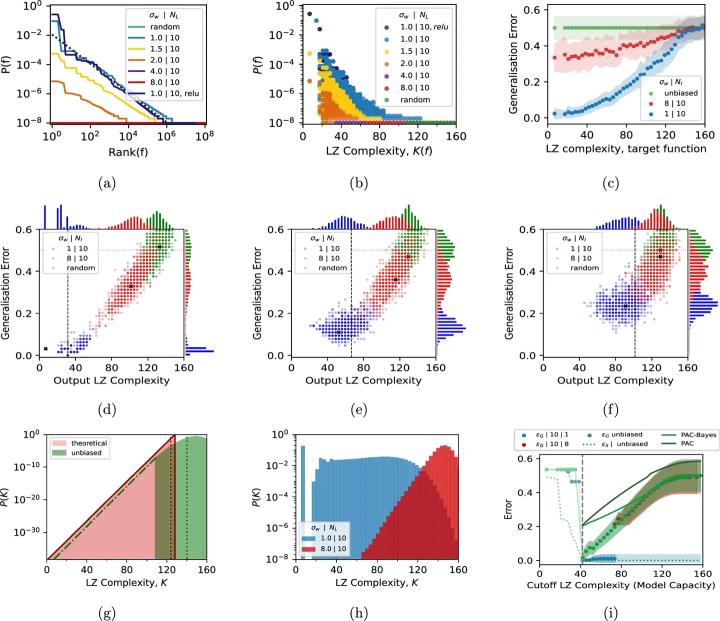
Исследователи изучили априорные вероятности функций, выраженных с помощью глубоких нейронных сетей. Априор представляет вероятность того, что случайно инициализированная глубокая нейровнная сеть сопоставит входные данные с определенным шаблоном выходных данных. Для логических функций, которые дают истинные или ложные результаты, исследование выявило экспоненциальный сдвиг в сторону функций с низкой описательной сложностью. Этот перекос согласуется с алгоритмической теорией информации, где более простые функции описываются короче.
Приоритет отдается функциям и сложности. (Иллюстрация: Nature Communications)
Профессор Ард Луис из Оксфордского университета объясняет: “Хотя мы знали, что глубокие нейронные сети полагаются на некоторую форму индуктивного стремления к простоте, точная природа этой бритвы оставалась неуловимой. Наша работа показывает, что предвзятость глубоких нейронных сетей противодействует экспоненциальному росту числа возможных сложных решений, позволяя эффективно их обобщать”.
Команда использовала показатели сложности Лемпеля-Зива (LZ) для количественной оценки простоты функций. Более простые функции имеют более короткие двоичные представления, и глубокие нейронные сети продемонстрировали явное предпочтение этим функциям перед более сложными. Это упрощение позволяет глубоким нейронным сетям избежать переобучения, отвергая большинство сложных функций, которые соответствуют обучающим данным, но не работают при невидимых входных данных.
Чтобы проверить, как это смещение влияет на производительность, исследователи изменили функции активации — математические механизмы, которые решают, “сработает” ли нейрон. Они заметили, что небольшие изменения в смещении простоты снижают способность сети к обобщению даже для простых логических функций.
Для более сложных целей производительность еще больше снизилась, иногда приближаясь к случайному угадыванию. Это открытие подчеркивает, насколько важна конкретная форма предпочтения простоты для успеха глубоких нейронных сетей.
В ходе исследования также было изучено, как производительность сети зависит от сложности данных. Классификация логических функций послужила модельной системой для исследования этой взаимосвязи. Полностью подключенные сети (FCN) были обучены на подмножествах логических входных данных и протестированы на невидимых данных.
Результаты показали, что сети с более сильным уклоном в простоту значительно лучше справлялись с более простыми целевыми функциями. Напротив, более слабые искажения привели к более слабому обобщению, особенно для простых данных. Эти результаты подчеркивают важность точной настройки искажений, позволяющей сетям сбалансировать гибкость и высокую производительность.
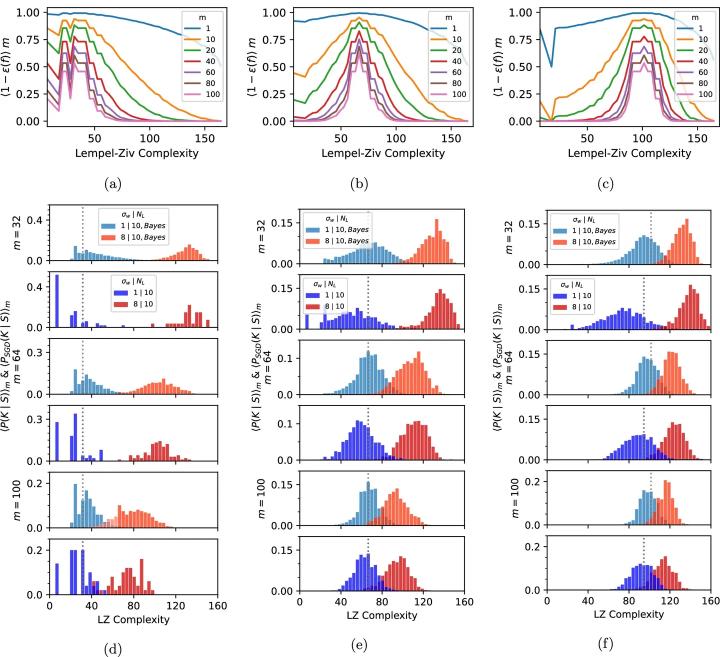
Взаимосвязь между структурированными данными и упрощением имеет решающее значение. Реальные данные часто демонстрируют присущие им шаблоны и закономерности, что согласуется с предпочтением DNNS простых решений. Эта естественная синергия помогает сетям выявлять значимые структуры без переобучения. Однако, когда сложность данных возрастает или отсутствуют четкие закономерности, глубокие нейронные сети сталкиваются с трудностями. Их производительность падает, что подчеркивает ограниченность возможности полагаться исключительно на простоту.
Эта взаимосвязь между простотой и структурой данных поднимает важные вопросы об адаптивности глубоких нейронных сетей. Например, что происходит, когда данные обучения значительно отклоняются от ожидаемых шаблонов?
Исследование показало, что даже незначительные отклонения в структуре данных могут нарушить способность сети к обобщению. Эти проблемы подчеркивают необходимость дальнейших исследований того, как сети могут адаптировать свои индуктивные искажения к более широкому спектру сложных данных.
Как данные обучения влияют на последующие данные. (Иллюстрация: Nature Communications)
Полученные данные указывают на интригующие параллели между глубокими нейронными сетями и природными системами. Смещение, наблюдаемое в глубоких нейронных сетях, отражает смещение простоты в эволюционных процессах, когда в биологических структурах часто возникают симметрия и регулярность.
Профессор Луис подчеркивает потенциал междисциплинарных исследований: “Наши результаты указывают на глубокие связи между алгоритмами обучения и фундаментальными принципами природы. Понимание этих параллелей может открыть новые возможности для исследований в обеих областях”.
Это исследование также затрагивает давнюю дискуссию в теории статистического обучения. Общепринятое мнение гласит, что модели с завышенными параметрами могут привести к переобучению, как это хорошо сформулировано в замечании Джона фон Неймана о том, что, задав слону четыре параметра, он заставляет его двигать хоботом в соответствии с пятью.
Однако DNN не оправдывают этих ожиданий, достигая высокой точности даже при огромной производительности. Полученные в исследовании данные о смещении в сторону простоты дают убедительное объяснение этому явлению.
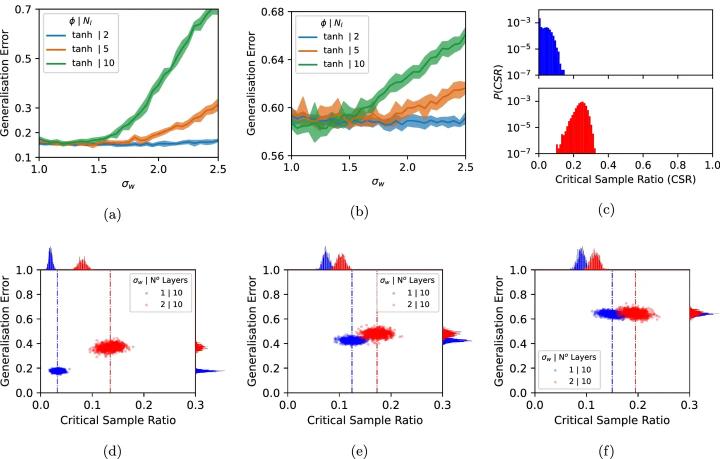
Более того, в исследовании освещается явление, известное как двойной спуск. В классической теории обучения производительность обычно достигает максимума при промежуточной сложности модели и снижается при дальнейшем увеличении сложности.
Данные MNIST и CIFAR-10. (Иллюстрация: Nature Communications)
Однако, по мере того, как их возможности продолжают расти, глубокие нейронные сети демонстрируют второе улучшение производительности, превосходящее обычные ожидания. Это явление двойного снижения подчеркивает, как глубокие нейронные сети используют свое обширное пространство параметров для согласования со структурированными данными, что еще больше повышает их способность к обобщению.
По мере того как искусственный интеллект продолжает внедряться в критически важные области, от здравоохранения до автономных транспортных средств, понимание того, как глубокие нейронные сети принимают свои решения, становится все более важным. Присущая ему склонность к простоте не только способствует обобщению, но и является отправной точкой для “открытия черного ящика” систем искусственного интеллекта. Разъясняя принципы, которыми руководствуется глубокая нейронная сеть при принятии решений, исследователи могут повысить прозрачность и подотчетность в приложениях искусственного интеллекта.
Однако проблемы остаются. Хотя простота во многом объясняет успех глубоких нейронных сетей, в исследовании признается, что конкретные архитектурные решения и методы обучения также влияют на производительность. Необходимы дальнейшие исследования, чтобы выявить дополнительные искажения и усовершенствовать модели для различных приложений.
Например, понимание того, как различия в функциях активации или алгоритмах обучения влияют на искажения, может дать более глубокое представление о механизмах, определяющих производительность глубоких нейронных сетей.
Результаты исследования выходят за рамки искусственного интеллекта. Проводя параллели между глубокими нейронными сетями и природными системами, исследователи могут изучить, как такие принципы, как предвзятость к простоте, проявляются в других областях.
Например, эволюционная биология и нейронаука могут извлечь пользу из этих открытий, проливающих свет на то, как природные системы сочетают сложность и простоту для достижения оптимальной функциональности.
Подводя итог, это новаторское исследование показывает, что выдающаяся производительность глубоких нейронных сетей обусловлена встроенным стремлением к простоте, которое отражает принципы, заложенные в природе. Это открытие не только углубляет наше понимание машинного обучения, но и открывает пути для инноваций в области искусственного интеллекта и за его пределами.
Поскольку глубокие нейронные сети продолжают определять будущее технологий, раскрытие тонкостей их индуктивных искажений будет иметь решающее значение для полного раскрытия их потенциала.