DrEureka, новый программный пакет с открытым исходным кодом, с которым может играть любой желающий, используется для обучения роботов выполнению реальных задач с использованием больших языковых моделей (LLM), таких как ChatGPT 4. Это система «симуляции реальности», то есть она обучает роботов в виртуальной среде с использованием имитируемой физики, прежде чем внедрить их в meatspace.
Доктор Джим Фан, один из разработчиков DrEureka, представил четвероногого робота Unitree Go1, который попал в заголовки газет. Это «недорогой» и хорошо поддерживаемый робот с открытым исходным кодом, что удобно, потому что даже с искусственным интеллектом роботы-питомцы по-прежнему подвержены повреждениям при падении. Что касается «низкой стоимости», что ж… Он продается на Amazon за 5 899 долларов США и имеет рейтинг в 1 звезду — можете не сомневаться.
«Dr» в DrEureka означает «рандомизация области» – это рандомизация таких переменных, как трение, масса, демпфирование, центр тяжести и т.д. в моделируемой среде.
С помощью нескольких подсказок в LLM, таком как ChatGPT, ИИ может написать код, который создает систему вознаграждений/штрафов для обучения бота в виртуальном пространстве, где 0 = неудача, а все, что выше 0, означает победу. Чем выше оценка, тем лучше.
Он может создавать параметры, минимизируя и максимально увеличивая точки отказа в таких областях, как упругость мяча, двигательная сила, степень свободы конечностей и демпфирование, и это лишь некоторые из них. Для LLM не составляет труда создавать их в огромных объемах, чтобы система обучения работала одновременно.
После каждой симуляции GPT также может проанализировать, насколько хорошо справился виртуальный робот и как его можно улучшить. Превышение или нарушение параметров, например, из-за перегрева двигателя или попытки сгибать конечность сверх ее возможностей, приведет к получению 0 баллов… И никому не нравится получать нулевые баллы, даже искусственному интеллекту.

Удержание мяча лучше, чем у ковбоя, скачущего верхом на быке на родео в исследовании Eureka Research
Для того, чтобы побудить LLM написать код, требуется инструктаж по технике безопасности – в противном случае, как выяснила команда, GPT будет стремиться к максимально возможной производительности и, по сути, «жульничать» в симуляторе без руководства. Это нормально в симуляторе, но в реальной жизни это может привести к перегреву двигателей или чрезмерному удлинению конечностей, что приведет к повреждению робота — исследователи называют это явление «дегенеративным поведением».
В одном из примеров своего неестественного поведения виртуальный робот-самоучка обнаружил, что может двигаться быстрее, упираясь бедром в землю и передвигаясь тремя ногами по полу, волоча бедро за собой. Честно говоря, это рисует мне несколько тревожную картину, но, конечно, хотя в симуляторе это было преимуществом, в реальном мире это привело к непродуктивной пересадке лица, когда робот попытался это сделать.
Поэтому исследователи посоветовали GPT быть особенно осторожной, помня о том, что робот будет тестироваться в реальных условиях, и в ответ на это GPT создала функции безопасности для таких параметров, как плавность хода, ориентация туловища, высота туловища и обеспечение того, чтобы двигатели робота не были перегружены. Если робот смошенничает и нарушит эти параметры, его функция вознаграждения будет выставлять более низкую оценку. Функции безопасности смягчают дегенеративное и неестественное поведение, например, ненужные толчки тазом.
Так как же он работал? Лучше, чем мы. Дреурека смог превзойти людей в обучении робота-дворняжки, показав 34%-ное преимущество в скорости движения вперед и 20%-ное в расстоянии, пройденном по реальной смешанной местности.
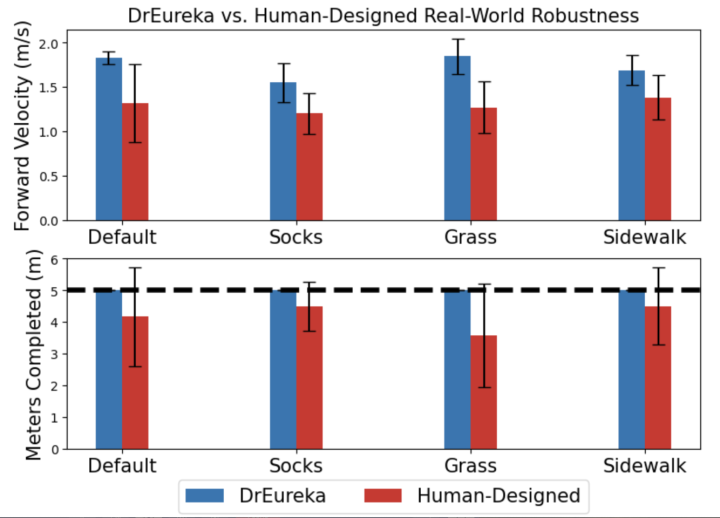
Основанная на GPT система обучения DrEureka успешно справляется с роботами, обученными людьми, в реальном мире исследований Eureka
Как? Что ж, по мнению исследователей, все дело в стиле преподавания. Люди предпочитают среду обучения в стиле учебной программы, разбивая задачи на небольшие этапы и пытаясь объяснить их по отдельности, в то время как GPT позволяет эффективно обучать всему и сразу. Это то, на что мы просто не способны.
DrEureka — первая в своем роде программа. Это позволяет «с нуля» перейти от симуляции к реальному миру. Представьте, что у вас почти нет практических знаний об окружающем мире, и вас выталкивают из гнезда, оставляя только разбираться в нем. Это нулевой результат.
Создатели DrEureka считают, что они могли бы еще больше усовершенствовать обучение в режиме реального времени, если бы могли предоставлять GPT обратную связь из реального мира. В настоящее время все тренировки на симуляторе проводятся с использованием данных из собственных проприоцептивных систем робота, но если бы GPT действительно могла видеть, что пошло не так, с помощью видеопотока в реальном времени, а не просто считывать информацию о сбоях при выполнении в логах робота, она могла бы гораздо эффективнее совершенствовать свои инструкции.
Среднестатистическому человеку требуется до полутора лет, чтобы научиться ходить, и я готов поспорить, что лишь крошечная часть от 1 процента людей может сделать это на мяче для йоги. И почему именно мяч для йоги, спросите вы? Конечно, их вдохновил цирк. Разве не все мы такие?
Вы можете посмотреть 4-минутное и 33-секундное видео без купюр, в котором робот-пес отправляется на прогулку на мяче для йоги, ни разу не останавливаясь, чтобы пописать на гидрант, здесь:
5-минутное видео с развертыванием DrEureka без купюр
Источник: Eureka Research
© «ПостИИ» (postii.ru), перевод на русский язык