
Недавний публичный релиз генеративной модели ИИ Hunyuan Video усилил текущие дискуссии о потенциале больших мультимодальных моделей зрения и языка, которые однажды смогут создавать целые фильмы.
Однако, как мы наблюдали, это сейчас очень отдаленная перспектива по ряду причин. Одна из них — это очень короткий временной интервал внимания большинства генераторов видео на ИИ, которые борются за поддержание согласованности даже в коротком одном кадре, не говоря уже о серии кадров.
Другая причина заключается в том, что последовательные ссылки на видео контент (например, исследуемые окружения, которые не должны изменяться случайным образом, если вы возвращаетесь по ним) могут быть достигнуты в диффузионных моделях только с помощью техник кастомизации, таких как низкоранговая адаптация (LoRA), что ограничивает возможности базовых моделей «из коробки».
Таким образом, развитие генеративного видео, похоже, может приостановиться, если не будут разработаны новые подходы к нарративной непрерывности.
Учитывая это, новое сотрудничество между США и Китаем предложило использовать инструктивные кулинарные видео в качестве возможного шаблона для будущих систем нарративной непрерывности.
Под названием VideoAuteur работа предлагает двухступенчатый процесс для создания обучающих кулинарных видео, используя связные состояния, объединяющие ключевые кадры и субтитры, достигая передовых результатов в – надо признать – не слишком популярной области.
На странице проекта VideoAuteur также представлены несколько довольно более интересных видео, которые используют ту же технику, такие как предложенный трейлер для (несуществующего) кроссовера Marvel/DC:
Страница также содержит аналогично оформленные рекламные видео для несуществующего сериала о животных от Netflix и рекламы автомобилей Tesla.
При разработке VideoAuteur авторы экспериментировали с разнообразными функциями потерь и другими новыми подходами. Для разработки рабочего процесса генерации рецептов они также собрали CookGen, крупнейший датасет, сосредоточенный на кулинарной тематике, состоящий из 200 000 видеоклипов с средней продолжительностью 9,5 секунд.
Средняя длина составляет 768,3 слова на видео, что делает CookGen самым обширно аннотированным датасетом такого рода. Использовались различные модели зрения/языка и другие подходы, чтобы обеспечить максимальную детализацию, актуальность и точность описаний.
Кулинарные видео были выбраны, потому что инструкции по кулинарии имеют структурированный и однозначный нарратив, что облегчает аннотирование и оценку. За исключением порнографических видео (которые, вероятно, скоро появятся в данной области), трудно представить другой жанр, который был бы столь же визуально и нарративно «формульным».
Авторы утверждают:
«Наш предложенный двухступенчатый авторегрессивный конвейер, который включает длинного нарративного директора и визуально ориентированную генерацию видео, демонстрирует многообещающие улучшения в семантической согласованности и визуальной точности сгенерированных длинных нарративных видео.»
«В ходе экспериментов с нашим датасетом мы наблюдаем улучшения в пространственной и временной согласованности в видеорядх.»
«Мы надеемся, что наша работа сможет способствовать дальнейшим исследованиям в области генерации длинных нарративных видео.»
Новое исследование называется VideoAuteur: Towards Long Narrative Video Generation и подготовлено восемью авторами из Университета Джонса Хопкинса, ByteDance и ByteDance Seed.
Кураторство датасета
Для разработки CookGen, который обеспечивает работу двухступенчатой генеративной системы по созданию видеорецептов с использованием ИИ, авторы использовали материалы из коллекций YouCook и HowTo100M. Авторы сравнивают масштаб CookGen с предыдущими датасетами, сосредоточенными на нарративном развитии в генеративном видео, такими как датасет Флинтстоуны, датасет мультфильмов Пороро, StoryGen, StoryStream от Tencent и VIST.
CookGen сосредотачивается на реальных нарративах, особенно на процедурных действиях, таких как приготовление пищи, предлагая более ясные и простые для разметки истории по сравнению с наборами данных комиксов, основанных на изображениях. Он превосходит существующий крупнейший набор данных StoryStream, имея в 150 раз больше кадров и в 5 раз более плотные текстовые описания.
Исследователи доработали модель аннотирования, использовав методологию LLaVA-NeXT в качестве основы. Псевдонимы автоматического распознавания речи (ASR), полученные для HowTo100M, использовались как «действия» для каждого видео, а затем были дополнительно уточнены с помощью больших языковых моделей (LLM).
Например, ChatGPT-4o использовался для создания набора заголовков и был настроен на взаимодействия предметов и объектов (такие как руки, работающие с кухонными приборами и пищей), атрибутами объектов и временной динамикой.
Поскольку скрипты ASR, как правило, содержат неточности и могут быть «шумными», метрика Intersection-over-Union (IoU) использовалась для измерения того, насколько близко заголовки соответствовали разделу видео, к которому они относились. Авторы отмечают, что это было критически важно для создания нарративной согласованности.
Кураторские клипы оценивались с использованием расстояния Фреше (FVD), которое измеряет различие между примерами исходной реальности и сгенерированными примерами, как с ключевыми кадрами, так и без них, достигая эффективного результата:
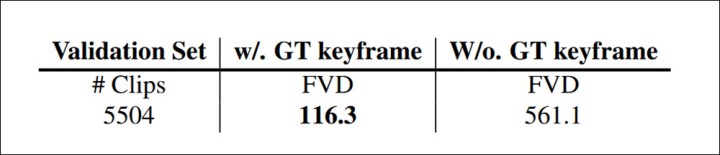
Использование FVD для оценки расстояния между видео, сгенерированными с новыми субтитрами, как с использованием ключевых кадров, так и без них, захваченных с образцовых видео.
Кроме того, клипы были оценены как GPT-4o, так и шестью человеческими аннотаторами, согласно определению «галлюцинации» от LLaVA-Hound (т.е. способности модели изобретать ложный контент).
Исследователи сравнили качество субтитров с коллекцией Qwen2-VL-72B, получив немного улучшенный результат.

Сравнение оценок FVD и оценок человека между Qwen2-VL-72B и коллекцией авторов.
Метод
Генеративная фаза VideoAuteur делится между Long Narrative Director (LND) и моделью генерации видео с визуальными условиями (VCVGM).
LND генерирует последовательность визуальных представлений или ключевых кадров, которые характеризуют поток нарратива, подобно «существенным моментам». VCVGM генерирует видеоклипы на основе этих выборов.
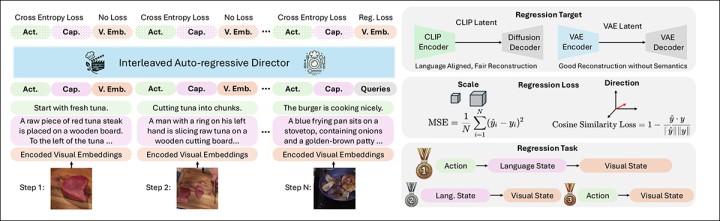
Схема обработки видеопотока VideoAuteur. Long Narrative Video Director делает соответствующий выбор для подачи в генеративный модуль на базе Seed-X.
Авторы подробно обсуждают различные преимущества интерливидного текстово-изображенческого директора и языкового директора ключевых кадров, приходя к выводу, что первый подход является более эффективным.
Интерливидный текстово-изображенческий директор генерирует последовательность, чередуя текстовые токены и визуальные эмбеддинги, используя авторегрессионную модель для предсказания следующего токена, основываясь на совокупном контексте как текста, так и изображений. Это обеспечивает тесное соответствие между визуальным рядом и текстом.
Напротив, языковой директор ключевых кадров синтезирует ключевые кадры, используя диффузионную модель, ориентированную на текст, основываясь исключительно на подписях, без включения визуальных эмбеддингов в процесс генерации.
Исследователи выяснили, что хотя языковой метод генерирует визуально привлекательные ключевые кадры, он не отличается последовательностью кадров, аргументируя тем, что интерливидный метод достигает более высоких оценок по реалистичности и визуальной согласованности. Они также отметили, что этот метод лучше способен изучать реалистичный визуальный стиль через обучение, хотя иногда встречаются повторяющиеся или шумные элементы.
Нетипично, в области исследований, где преобладает использование Stable Diffusion и Flux в рабочих процессах, авторы использовали базовую модель многомодального LLM нового поколения SEED-X от Tencent с 7 миллиардами параметров для своей генеративной цепочки (хотя эта модель использует стабильный выпуск Stable Diffusion от Stability.ai для ограниченной части своей архитектуры).
Авторы утверждают:
‘В отличие от классической цепочки Image-to-Video (I2V), которая использует изображение в качестве начального кадра, наш подход основывается на [регрессионных визуальных латентах] в качестве непрерывных условий на протяжении всей [последовательности].
‘Кроме того, мы улучшаем устойчивость и качество генерируемых видео, адаптируя модель для работы с шумными визуальными эмбеддингами, так как регрессионные визуальные латенты могут быть далеки от идеала из-за ошибок регрессии.\\’
Хотя типичные визуально-условные генеративные линии этого типа часто используют начальные ключевые кадры в качестве отправной точки для управления моделью, VideoAuteur расширяет эту парадигму, генерируя многокомпонентные визуальные состояния в семантически согласованном латентном пространстве, избегая потенциального искажения, основанного на ‘начальных кадрах\\’.
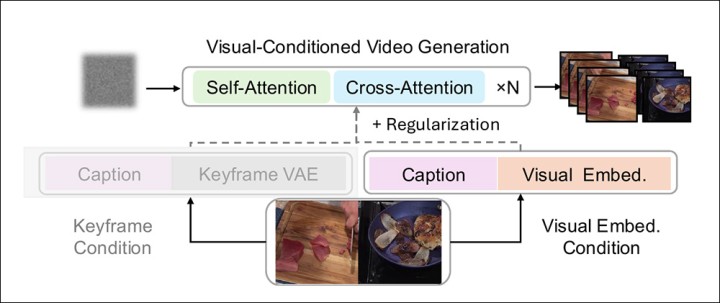
Схема использования визуальных эмбеддингов состояний как превосходного метода кондиционирования.
В соответствии с методами SeedStory, исследователи используют SEED-X для применения LoRA тонкой настройки на своем наборе данных по нарративам, загадочно описывая результат как «модель в стиле Сора», предварительно обученную на больших объемах пар видео/текст и способную приниматься как визуальные, так и текстовые подсказки и условия.
Для разработки модели было использовано 32,000 нарративных видео, из которых 1,000 были отложены в качестве валидационных образцов. Видео были обрезаны до 448 пикселей с короткой стороны, а затем центрально обрезаны до 448x448px.
Для обучения генерация нарративов была оценена в основном на валидационном наборе YouCook2. Набор Howto100M использовался для оценки качества данных и также для генерации изображений в видео.
Для потерь визуального кондиционирования авторы использовали диффузионные потери из DiT и работу 2024 года, основанную на Stable Diffusion.
Чтобы доказать свое утверждение, что чередование является превосходным подходом, авторы сопоставили VideoAuteur с несколькими методами, которые полагаются исключительно на текстовый ввод: EMU-2, SEED-X, SDXL и FLUX.1-schnell (FLUX.1-s).

Учитывая глобальный запрос «Пошаговое руководство по приготовлению мапо тофу», интерливированный директор (режиссер) последовательно генерирует действия, заголовки и встраивания изображений, чтобы рассказать о процессе. Первые две строки показывают ключевые кадры, декодированные из латентных пространств EMU-2 и SEED-X. Эти изображения реалистичны и последовательны, но менее отшлифованы, чем те, что получены из продвинутых моделей, таких как SDXL и FLUX.
Авторы утверждают:
«Языково-центрированный подход, использующий текстовые модели для создания изображений, производит визуально привлекательные ключевые кадры, но страдает от недостатка последовательности между кадрами из-за ограниченной взаимной информации. В отличие от этого, метод интерливированной генерации использует визуальные латентные представления, соотносящиеся с языком, достигая реалистичного визуального стиля через обучение.»
«Тем не менее, он иногда генерирует изображения с повторяющимися или шумными элементами, так как автогрессивная модель испытывает трудности с созданием точных встраиваний за одно прохождение.»
Человеческая оценка дополнительно подтверждает мнение авторов о повышенной эффективности интерливированного подхода, при этом интерливированные методы достигают самых высоких оценок в опросе.
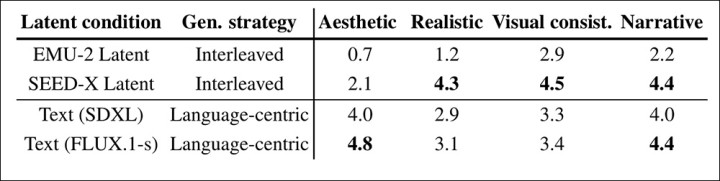
Сравнение подходов из исследования, проведенного для данной статьи.
Однако мы отмечаем, что языковые подходы достигают лучших эстетических оценок. Авторы, однако, утверждают, что это не является центральной проблемой в создании долгих повествовательных видео.
Сегменты, созданные для видео о создании пиццы, от VideoAuteur.
Заключение
Наибольшей популярностью среди исследований в контексте этой задачи, а именно, нарративной последовательности в генерации длинных видео, пользуются отдельные изображения. К таким проектам относятся DreamStory, StoryDiffusion, TheaterGen и ConsiStory от NVIDIA.
В некотором смысле, VideoAuteur также попадает в эту ‘статическую’ категорию, поскольку использует исходные изображения, на основе которых генерируются сегменты клипов. Тем не менее, сочетание видео и семантического контента приближает процесс к практическому конвейеру.